

OOPS
Errors
Pandas
File Handling
- By using Pandas we can retrieve Data from Text File
- Through PANDAS we can interact with TEXT files and retieve the data and store in TUPLE
- Create Data Frame:
- Default seperator " , "
- Considered delimiter as ','
- We can use delimiter as key word instad of sep
- Used pandas to extract the data from textfile
- Used Openpyxl package to export the data into excel workbook
- Select manually begining row and end row in combo box
- Begining row number(min row) should be greater than max row(end row)
- Openpyxl creates excel workbook itself., you need not refer any workbook
- Click on below image to watch video
- If TEXT file doesn't consits of Header, then Pandas by default assigns headers for dataframe
- Create Dataframe by making date field as Index_column, then do the slicing
- names List considered as Headers
- 'names' is a key word which is used to refer header list
- "index_col" denotes about row index
- We can assign index column as per our requirement
- Save the text file in a list
- Skip the rows of 0,3 from dataframe
- enables to skip the blank lines
- Skip 5 rows from bottom
- Create dataframe based on required column names\numbers
- Print N rows from top
- Consider multiple columns as index columns
- Select the chart type from combo box
- Select the column header from list box
- Click the button to display and save the chart
- Reads the textfile into filesize 2
- Missing values marked as NaN
- Import the data from Text file by creating Dataframe
- Export the Data_Frame and Slicing methods into Excel through PANDAS
- Create Bar charts in excel workbook using VBA Macros
- Fill Max value bar with Yellow for all the charts
- Enables the user to slice the data based on Index position
Pandas - Text File

Import Pandas as Pd
df = pd.read_csv('Sales.txt')

df = pd.read_csv('Sales.txt', sep = ',')
df = pd.read_csv('Sales.txt', delimiter = ',')
Export the data from Text file to Excel workbook


df = pd.read_csv('Sales.txt', header=None)
df = pd.read_csv('Sales.txt', index_col=0, parse_dates=True)
names=['First','Second','Third']
df = pd.read_csv('Sales.txt', names = names )
names=['First','Second','Third']
df = pd.read_csv('Sales.txt', names = names, index_col = 'First' )
print(list(open('Sales.txt')))
df = pd.read_csv('Sales.txt', skiprows = [0,3])
df = pd.read_csv("Sales.txt", skip_blank_lines=True)
df = pd.read_csv('Sales.txt', skipfooter = 5)
df = pd.read_csv("Sales.txt", usecols = [0,1])
df = pd.read_csv("Sales.txt", usecols = ['Item','Price'])

df = pd.read_csv('Sales.txt', nrows = 5)
df = pd.read_csv("Sales.txt", index_col = [0,1])



df = pd.read_csv('Sales.txt', chunksize = 2)
Handling with Missing values
df = pd.read_csv('Sales_Null_Values.txt')
Data extraction through Slicing

Pandas - iloc

and Operator

or Operator
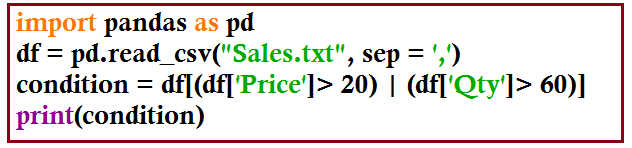
Group by
print(dir(df.groupby('Item')))

stack
df = pd.read_csv("Sales.txt", sep = ',')
s = df.stack()
 Hi Welcome to Python Tutorial.
Hi Welcome to Python Tutorial.
Thanks,
Pavan Kumar Gundlapalli