

OOPS
Errors
Pandas
File Handling
- Beautifulsoup is a libraray which enables to retrive data from HTML and XML files
- Difference between Beautifulsoup and Scrapy is, soup is library which enabels to pull the data from web, whereas SCRAPY is a complete frame work
- There are two types of PARSERS
- lxml
- html5lib
- (i)all text
- (ii)Kind of tree structure
- tag
- Navigablestring
- BeautifulSoup
- Comment
- Child: is a tag inside a tag
- parent: when a tag having inside
- Sibling: is a tag for same parent
- Through get request we can download the data\webpage
- It sends the request to the web server
- All the examples prepared based on below mentioned examples
Parsers
Perameters of Beautifulsoup
Classification of data
Soup classified the data into 4 ways:
Tags
request library
All the examples prepared based on below mentioned link:
https://en.wikipedia.org/wiki/Web_scraping:
Print entire text under a class


Print all Heading Styles

Print all Links in a class

Print all Links and text

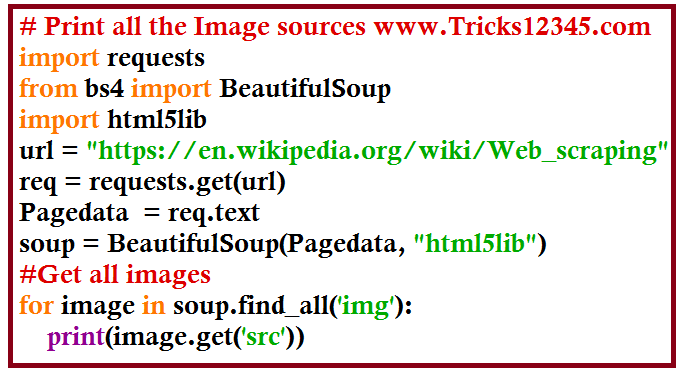
Print all Image sources
Beautifulsoup first Anchor text in a Paragraph

Beautifulsoup first Paragraph under a class

Beautifulsoup - Print all paragraphs from a web page

Beautifulsoup - Print particular href in a class
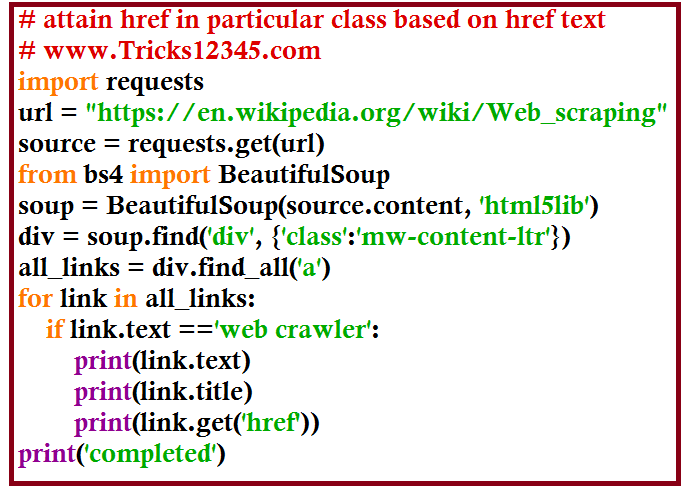
Beautifulsoup - Print particular href in a class
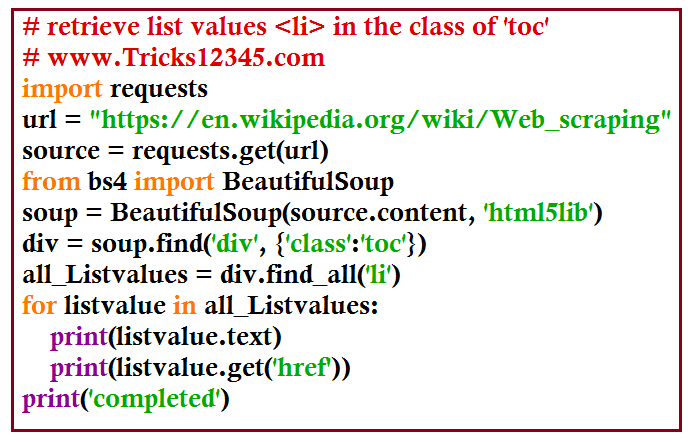
Beautifulsoup - Retrieve sub list values
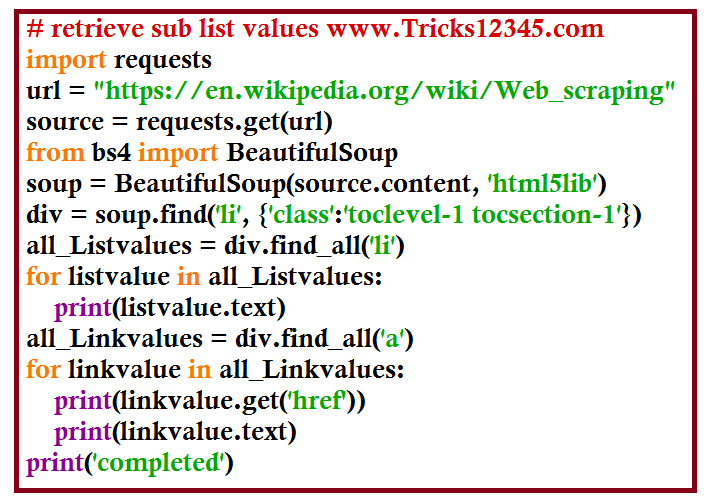
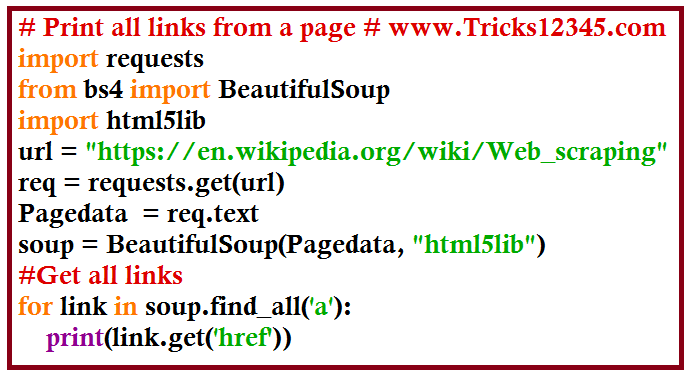
Beautifulsoup - Print all links from a web page
 Hi Welcome to Python Tutorial.
Hi Welcome to Python Tutorial.
Thanks,
Pavan Kumar Gundlapalli